Kategoryzacja zmiennych
Kolejną czynnością często wykonywaną na etapie porządkowania danych jest kategoryzacja zmiennych. O co tutaj chodzi. Znów popatrzmy na przykład:
| Country | Age | Salary | Product purchases |
|---|---|---|---|
| France | 44.0 | 72000.0 | Yes |
| Spain | 27.0 | 48000.0 | Yes |
| Germany | 30.0 | 54000.0 | No |
| Spain | 38.0 | 61000.0 | No |
| Germany | 40.0 | Yes | |
| France | 35.0 | 58000.0 | No |
| Spain | 52000.0 | No |
Wśród atrybutów powyższej tabeli, dwie cechy można skategoryzować. Są to Country _u _Product purchases. Pierwsza z nich zawiera wartości ze zbioru trój-wartościowego: (France, Spain, Germany), a druga ze zbioru dwu-wartościowego: (Yes, No).
Kategoryzacja zmiennych jest istotna co najmniej z dwóch powodów:
- pozwala na optymalizację zajętości pamięci przez daną strukturę danych
- jest niezbędna w algorytmach uczenia maszynowego, które wymagają na wejściu wartości numerycznych. Kategoryzacja w tym przypadku pozwala zakodować wartości danej kategorii jako numeryczne identyfikatory
Przykład w Python
I znowu, do kategoryzacji danej cechy można wykorzystać moduł preprocessing w bibliotece scikit-learn oraz klasę LabelEncoder
from sklearn.preprocessing import LabelEncoder
labelEncoder_x = LabelEncoder()
X[:,0] = labelEncoder_x.fit_transform(X[:,0])
Przyjmuje ona jako parametr metody fit_transform kolumnę reprezentującą dane danej cechy i zwraca wartości danej cechy w postaci numerycznej, kodując unikalnie każdą wartość:
X
Out[3]:
array([[0, 44.0, 72000.0],
[2, 27.0, 48000.0],
[1, 30.0, 54000.0],
[2, 38.0, 61000.0],
[1, 40.0, 63777.77777777778],
[0, 35.0, 58000.0],
[2, 38.77777777777778, 52000.0],
[0, 48.0, 79000.0],
[1, 50.0, 83000.0],
[0, 37.0, 67000.0]], dtype=object)
Jest niestety z takim sposobem kodowania jeden problem. Kolejne wartości nienumeryczne są kodowane z wykorzystaniem kolejnych wartości numerycznych, co będzie w algorytmach uczenia maszynowego powodować, że mogą być one traktowane jako bardziej lub mniej znaczące, ze względu na swoją wartość liczbową.
Przykład w R
Jest to zdecydowanie prostsze, gdyż możemy zdefiniować cechę jako skategoryzowaną i już:
dataset$Country = factor(dataset$Country,
c('Spain', 'France', 'Germany'),
c(1,2,3))
Dummy encoding
Innym sposobem kodowania zmiennych skategoryzowanych, który radzi sobie z problemem opisanym powyżej jest kodowanie wartości za pomocą tylu cech ile unikalnych wartości występuje w kategorii. Jeśli kolumna Country w naszym przykładzie ma trzy wartości, to każdą z tych wartości możemy zapisać w trzech nowych cechach, gdzie każda z tych cech przyjmuje wartość 0 lub 1:
| Country | France | Germany | Spain |
|---|---|---|---|
| France | 1 | 0 | 0 |
| Germany | 0 | 1 | 0 |
| Spain | 0 | 0 | 1 |
Przykład w Python
from klearn.preprocessing import OneHotEncoder
oneHotEncoder = OneHotEncoder(categorical_features = [0])
X = oneHotEncoder.fit_transform(X).toarray()
Parametr categorical_features przyjmuje wartość, która jest listą indeksów, wskazującą na zmiennej, które mają zostać zakodowane.
W wyniku dostaniemy następującą strukturę:
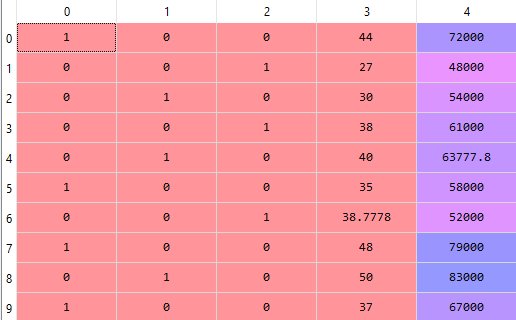
Wykorzystanie zmiennych dummy w modelu
Tak utworzone cechy wchodzą następnie jako zmienne niezależne do modelu. Istotne jest, aby do modelu wprowadzać n-1 cech, gdzie n oznacza liczbę kategorii dla cechy wyjściowej. Chodzi tutaj o to, że zmienna n jest zależna od zmiennych pozostałych i da się ją zawsze przedstawić jako n3 = 1 - n2 - n1. Angielski termin na taką zależności to multicollinearity.